Oczyszczanie danych z użyciem OpenRefine
 |
|  |
| 
 Zbieranie metadanych podczas digitalizacji zasobów archiwalnych nie jest prostym zajęciem. Nazwy miejsc, wydarzeń, nazwiska osób wymienianych w dokumentach często różnią się od dzisiejszej pisowni. Nazwy mają różne wersje, aliasy, w dokumentach pojawiają się literówki itp. Co prawda nowoczesne przeszukiwarki jak Google często potrafią rozpoznać często spotykane literówki - jeśli wpiszemy “Kowakski” otrzymamy:
Zbieranie metadanych podczas digitalizacji zasobów archiwalnych nie jest prostym zajęciem. Nazwy miejsc, wydarzeń, nazwiska osób wymienianych w dokumentach często różnią się od dzisiejszej pisowni. Nazwy mają różne wersje, aliasy, w dokumentach pojawiają się literówki itp. Co prawda nowoczesne przeszukiwarki jak Google często potrafią rozpoznać często spotykane literówki - jeśli wpiszemy “Kowakski” otrzymamy:
Pokazane są wyniki dla Kowalski
Szukaj zamiast tego Kowakski,
ale działa to najlepiej dla często spotykanych nazw czy imion i dla błędów. W projekcie, w którym chcielibyśmy przedstawić dane jako Linked Open Data, ważne jest mieć czyste dane, bez błędów i z zidentyfikowanymi wersjami, jeśli takie istnieją.
Jako przykład weźmiemy nazwiska (zbieramy także nazwy miejsc, wydarzeń historycznych i inne). Samo imię i nazwisko zwykle nie identyfikuje osoby - może być wiele osób o takim samym imieniu i nazwisku. Kiedy już zidentyfikujemy osobę, często okazuje się, że jej nazwisko występuje w wielu wariantach. Są wersje w różnych językach, osoba mogła używać pseudonimu, przydomka, zmienić nazwisko (przed albo po małżeństwie), dodać tytuły itp. Poddani i obywatele często używają przydomka dla określenie swoich przywódców. Jak znaleźć się w tej gmatwaninie?
Dla osób wymienionych w dokumentach archiwalnych wybraliśmy kilka prostych reguł. Sa one nieco arbitralne, ale służa nam dobrze:
-
Używamy jednego standardowego imienia i nazwiska dla jednej osoby. Nazwiska alternatywne, wersje w innych językach itp. są notowane także, aby ułatwić wyszukiwanie. Używamy wersji polskiej nazwiska, jeśli to możliwe, i wersji używanej w Wikipedii (polskiej lub w innym języku) jeśli jest to stosowne.
-
Zapisujemy dane osoby jako “nazwisko, imię (imiona)” w tej kolejności. Nawet ta prosta reguła powoduje czasem trudności, gdyż nie zawsze jest łatwo określić, która część jest imieniem a która nazwiskiem. Wyjątkiem od tej reguły są osoby publiczne takie jak królowie, papieże itp. Dla których podajemy popularne lub oficjalne brzmiene (Mieszko I, Jan Paweł II itp.)
-
Przypisujemy każdej osobie unikalny identyfikator który generujemy sami. O potrzebie używania unikalnych identyfikatorów mozna więcej przeczytać w blogu, Jeśli to możliwe, korelujemy ten identyfikator z dwoma popularnymi (i w miarę trwałymi) rejestrami: Wikidanymi i VIAF. Spotykamy jednak osoby, o których nikt nie napisał artykułu w Wikipedii w żadnym języku, i w konsekwencji brak im identyfikatora Wikidata. Są osoby które nigdy nie napisały książki i brak jest ich w rejestrze VIAF, który zbiera dane z bibliotek narodowych świata. Dla nich tworzymy krótki opis, dodajemy odnośniki i jak dla innych tworzymy nasz identyfikator.
Następnym etapem jest sprawdzenie zebranych zapisów nazwisk (w chwili obecnej mamy ich około 80 tysięcy) i doprowadzenie ich do standardu. Pracujemy w sekcjach, typowo z danymi jednej kolekcji archiwalnej, ale i tak są to dziesiątki tysięcy rekordów. Można użyć uniwersalne narzędzie - arkusz rozliczeniowy - i wykorzystując takie funkcje jak sortowanie, filtrowanie, wyszukiwanie i zastępowanie wykonać dużą część pracy, Znaleźliśmy jednak bardziej wyspecjalizowany program - OpenRefine - który okazał się być o wiele bardziej przydatny dla wykonania tego zadania. OpeRefine (rozprowadzany jako otwarte oprogramowanie) wyrósł z projektu Google, nazywany wtedy Google Refine (mocno związany z nieistniejącym już projektem Freebase1) i został oddany społeczności otwartego oprogramowania która dalej go udoskonala. OpenRefine został stworzony specjalnie do zadania czyszczenia i udoskonalenia danych.
OpenRefine
OpenRefine jest zaawansowanym programem z bardzo skutecznymi narzędziami. Może być zainstalowany na pececie i pracuje jako serwer webowy, to znaczy że pracujemy z nim w oknie dowolnej przeglądarki internetowej. Dane są zapisywane tylko lokalnie, nie ma więc obaw o niechciane upublicznianie danych. Jeśli chcesz pracować na innym komputerze, łatwo jest eksportować i importować projekt w trakcie pracy, przenosząc go np. na pendrive.
OpenRefine jest bogaty w opcje, funkcje i możliwości. Nie będę próbował opisać ich wszystkich; moim celem jest wprowadzenie go jako narzędzia do pracy przy archiwach, i pokazanie jego najważniejszych możliwości, wykorzystanych przy digitalizacji zasobów Instytutu Piłsudskiego w Ameryce.
Import
OpenRefine deklaruje możliwość importu danych w różnych formatach, ale szybkie importy udawały się tylko z danych rozdzielonych przecinkiem (CSV) albo znakiem tabulatora (TSV). Lewa kolumna powinna zawierać klucz do tabeli - często używany przy przenoszeniu danych z innej bazy danych. Jeśli nie ma klucza, można wprowadzić tu liczby sekwencyjne (1,2,3 …). Pierwszy rząd powinien zawierać tytuły kolumn. Tworząc nowy projekt w OpenRefine zaczynamy od importu danych. Wielkość nie jest ograniczona, ale szybkość wielu operacji zależy od liczby wierszy - zwykły komputer radził sobie bez trudu z 30 czy 50 tysiącami rekordów bez znaczących opóźnień. Podczas importu wybieramy kodowanie (typowo utf-8, ale dane mogą być zakodowane inaczej). Po imporcie pracujemy już tylko z projektem OpenRefine, a oryginalne dane odkładamy na bok.
OpenRefine a arkusz kalkulacyjny
Podobnie jak typowy arkusz kalkulacyjny, OpenRefine obrabia płaski, dwuwymiarowy zestaw danych z kolumnami zawierającymi różne rodzaje danych, i wierszami zawierającymi rekordy. OpenRefine pozwala na tworzenie nowych kolumn, przemianowanie istniejących, przesuwanie ich i tak dalej.
W odróżnieniu od arkusza rozliczeniowego, komórki w OpenRefine zawierają tylko dane, nie formuły. Wygląda to jak ograniczenie, ale nie jest nim naprawdę - dane mogą być transformowane na wiele sposobów używając bogatego zestawu funkcji opisanych szczegółowo w instrukcji. Można zmienić wartości w komórkach danej kolumny, stworzyć kolumnę z nowymi danymi z danych z jednej, wielu kolumn a nawet kolumn z innych projektów.
Fasety (Facets)
Jedną z najskuteczniejszych przy obróbce danych możliwości OpenRefine sa aspekty albo fasety2. Wybierając na przykład faset tekstowy należący do kolumny “nazwa”, które zawiera nazwiska i imiona osób, otrzymujemy ich listę. Jeśli dane imię i nazwisko występuje w wielu rzędach (rekordach), w liście fasetów pojawia się tylko raz. Kliknięcie na dany faset wyświetla w drugiej części ekranu wszystkie rekordy w których on występuje.
Dodając faset tekstowy do przykładowego zestawu danych zawierającego 13 772 rekordy otrzymaliśmy 6 674 różne fasety (różniące się od siebie nazwiska). Te liczby są wyświetlone na ekranie, pozwalające na widok na dane z lotu ptaka. Jako bonus dostajemy także histogram liczby trafień dla każdego faseta, i to nie nie tylko do oglądania: używając suwaczka możemy ograniczyć widok danych do tych nazwisk, które występują przykładowo w co najmniej 50 rekordach. Z wyklresu poniżej widać, że nazwiska występują najczęsciej po kilka razy, ale są takie, które występują 350 razy.
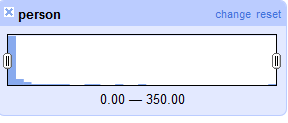
Podobne wykresy są pokazywane gdziekolwiek występuje jakieś grupowanie danych, na przykład w klastrach (partrz niżej). Można dodać inne nazwiska (lub ich wersje) do tej listy wybierając inna wartośc i używając znacznika “dołącz” lub “rozłącz”, Można także użyć fasety z innych kolumn. Na przykład tworząc faset w kolumnie “folder” i wybierając jeden z wielu folderów ograniczy wyświetlone dane do rekordów z danego folderu
Przeszukiwanie
Funkcja ta działa podobnie do funkcji “filtru” w arkuszu kalkulacyjnym. Dodając filtr testowy dla danej kolumny, możemy ograniczyć wyświetlone fasety do jednego nazwiska, albo użyć dowolnego kryterium (uwzględniając “case sensitivity” czy, dla zaawansowanych “wyrażenia regularne”). Przykładowo,
wprowadzając “chod” do okienka filtru, otrzymujemy następujące fasety:
Chodacki 35
Chodacki, M 1
Chodacki, M. 7
Chodacki, M. S. 3
Chodacki, M., mjr 8
Chodacki, Marian 3
Chodacki, mjr 8
Chodecki, mjr dypl. 1
Liczba po nazwisku wskazuje liczbę rekordów w których ta wersja występuje. Możemy teraz “dołączyć” wszystkie, i po upewnieniu się czy wszystkie odnoszą się do tej samej osoby, doprowadzić nazwisko do formy standardowej (w naszym przypadku jest to “Chodacki, Marian”, jeden z dyrektorów wykonawczych Instytutu Piłsduskiego)
Grupowanie (tworzenie klastrów)
W miarę wchodzenia w bardziej zaawansowane możliwości rosną problemy z językiem polskim i tłumaczeniem terminów, napotkane już przy opisie fasetów. W ogólności połączenie jakichś obiektów lub pojęć w grupy daje nam obiekt zwany zgrupowaniem, klastrem, zgęstkiem, gronem itp. Dalej będziemy używali najczęściej stosowanej nazwy klaster.
Wychodzimy już poza możliwości arkusza kalkulacyjnego. Używając jednego z całego szeregu algorytmów, możemy poprosić OpenRefine o zgrupowanie nazwisk które “wyglądają podobnie”, a więc mogą potencjalnie reprezentować tę sama osobę. Przykładowo,
używając najszybszego algorytmu (key collision - fingerprint) otrzymamy wśród wielu takich klastrów następujące zgrupowanie:
- Vargas, Getulio(30 rows)
- Vargas, Getúlio(3 rows)
- Getulio, Vargas(1 rows)
z opcją zastąpienia tych wersji jedną z trzech, albo całkiem nową. W tym wypadku wybieramy drugi wariant zastępując nazwisko we wszystkich 34 rekordach wersją ‘Vargas, Getúlio’ - z kontekstu 34 dokumentów - prezydent Argentyny. Później przypiszemy tej osobie identyfikator Wikidanych (Q156844) i VIAF (24623952).
Dla ciekawych, ten konkretny algorytm wewnętrznie usuwa spacje z początku i końca, znaki przestankowe i kontrolne, zamienia cały tekst na małe litery, usuwa słowa występujące wiele razy, zastępuje litery ze znakami diakrytycznymi ich najbliższym odpowiednikiem ASCII, i w końcu grupuje zapisy które mają takie same słowa, niezależnie od ich kolejności.
Nie trzeba studiować algorytmów aby je używać - po prostu próbujemy różne i wybieramy te klastry które mają sens. Opis algorytmów jest ciekawą lektura samą w sobie, na przykład w opisie metody “N-gram fingerprint” podany jest przykład słów Krzysztof, Kryzysztof i Krzystof które ten algorytm wyłapie w klaster, gdyż używają tych samych liter.
Transformacje
Można dokonać transformacji na danych w dowolnej kolumnie, albo stworzyć nową kolumnę z zmienionymi danymi. Kolumna może obejmować wszystkie dane, albo tylko ich część wybranych przez użycie fasetów i/lub filtrów. Funkcje działają podobnie jak w arkuszu kalkulacyjnym, ale ich składnia jest bliższa języka Java. Najlepiej jest używać wbudowanych funkcji “General Refine Expression Language” - GREL, które są dobrze udokumentowane, choć instrukcja programu zapewnia, że akceptowane są inne języki jak Python). W GREL znajdziemy większość typowych funkcji (logicznych, manipulacji tekstu, matryc, dat itp.), a także sporo wyspecjalizowanych funkcji jak wspomniana możliwości sięgania po dane z innego projektu. Często używane funkcje umieszczone są w menu dostępnym dla każdej kolumny, jak np. przycięcie (‘trim’) która usuwa spacje przed i po tekście, czy złożenie kolejnych spacji (‘collapse consecutive whitespaces’). Polecam ich użycie na początku pracy, aby pozbyć się trudnych do znalezienia efektów powodujących to, że “Kowalski, Jan”, "Kowalski, Jan” i Kowalski, Jan “ występują jako 3 różne osoby, a nie jedna.
Działania na kolumnach
Często stosowaną operacją na kolumnie jest Stwórz kolumnę z danych tej kolumny. Bez wprowadzania żadnej transformacji funkcja ta po prostu kopiuje daną kolumnę z jej wartościami. Ponieważ w naszej pracy nad nazwiskami zawsze chcemy wiedzieć, które nazwiska zostały poprawione, pierwszym zadaniem jest duplikacja kolumny “nazwiska” dając jej nazwę “nazwiska oryginalne”. Kolumna ta posłuży później do zaznaczenia tych rekordów, w których nastąpiły zmiany i potrzeba jest ich uaktualnienie w oryginalnej bazie danych skąd dane pochodzą
Tworząc nowa kolumnę można użyć dowolnej funkcji GREL dla transformacji, extracji czy innej operacji na danych.
Pobieranie danych z WWW (fetch an URL)
Tworząc nową kolumnę łatwo jest stworzyć adres internetowy jakiejś strony, np. ["https://pl.wikipedia.org/wiki/" + value] da adres artykułu w polskiej Wikipedii o tytule takim jak zawartość komórki. Operacja pobierania ma parametr “przepustnicy” aby zwolnić wysyłanie zapytań (niektóre serwisy nie pozwalają na zbyt częste połączenia z tego samego komputera). Pobrane dane można potem analizować wybierając poszukiwaną informację jak pożądany opis, identyfikator itp. Ta metoda pozwala wzbogacić dane o dodatkową informację dostępną w innym miejscu w sieci.
Uspójnianie (reconciling)
Uspójnianie jest funkcją jeszcze bardziej zaawansowana niż pobieranie, ale do jej użycia potrzebny jest zewnętrzny (lub lokalny) serwis. Istnieją dostępne serwisy (używaliśmy takiego do znajdywania identyfikatorów VIAF), można też uruchomić własny instalując program na komputerze. Po konfiguracji i uruchomieniu serwisu uspójniania, pojawi się nowa kolumna z wynikami. Serwis używa algorytmu aby zgadnąć, jak trafny jest wynik, i pokaże pewną (konfigurowalną) liczbe alternatyw. Można wtedy przyjrzeć się danym, i wybrać najlepsze trafienie, zaakceptować lub odrzucić. W naszym przypadku proces ten bardzo przyspieszył znajdowanie identyfikatorów VIAF.
Operacje na komórkach
Niezależnie od tego czy wybierasz faset, ograniczając liczbę wierszy nad którymi pracujesz, czy pracujesz nad całym zestawem danych, możesz edytować każdą komórkę. Na przykład w kolumnie z duplikatem nazwiska możesz wpisać znaleziony identyfikator Wikidata. Masz wtedy opcję Zastosuj albo Zastosuj do wszystkich identycznych komórek. Ta druga opcja wypełni wszystkie identyczne komórki w wybranym zestawie rekordów nowa wartością.
Podobna operacja może być wykonana na fasecie który także jest edytowalny - zmiana wartości ‘Kowakski’ na ‘Kowalski’ zaktualizuje tę wartość we wszystkich rekordach.
Cofnij/Przywróć
Jak w każdym szanującym się programie, można cofnąć i przywrócić wykonana operację. Projekt utrzymuje listę wszystkich operacji (z krótkim opisem) i zawsze można wrócić do stanu sprzed kilku kroków (a nawet do stanu z dnia wczorajszego).
Eksport
Po zakończeniu pracy można wyeksportować całą tabelę jako CSV lub TSV, co jest najprostsze dla dalszej pracy (również dlatego, że te formaty są prawie uniwersalnie akceptowane). Można też utworzyć niestandardowy eksport wybierając niektóre pola, eksportować dane jako HTML do wyświetlenia w przeglądarce lub na stronie Internetowej, przenieść wprost do arkusza Google Sheets i inne.
Podsumowanie
W naszej pracy nad danymi do projektu Linked Open data odkryliśmy, że OpenRefine jest ogromnie użytecznym programem do czyszczenia i udoskonalania danych wprowadzanych ręcznie przez wiele osób. Mam nadzieje, że to krótkie wprowadzenie zachęci Wa do spróbowania go.
___________________
Przypisy
1) Dane Freebase zostały przekazane Google i są teraz dostępna poprzez Google API
2) Patrz “Nawigacja Fasetowa” w Wikpedii
Czytaj więcej
- "Cleaning Data with Refine" w School od Data
- Wykorzystanie OpenRefine w blogu "The Programming Historian"
- Wstęp i linki do różnych wideo o OpenRefine w blogu L'Endormitoire (po angielsku)
Marek Zieliński
Artykuł ukazał się w sierpniu 2017 w Blogu archiwistów i bibliotekarzy Instytutu Piłsudskiego
Może Cię też zainteresować
Poprawiony (czwartek, 20 lipca 2017 16:15)

Bezpośrednie wsparcie
dla archiwów Ukrainy
Support Heritage
in Ukraine
![]()
za pośrednictwem
Museum & Archives
GALT
szczegóły
![]()
Archiwum Narodowe
w Krakowie

Instytut
Józefa Piłsudskiego
w Ameryce
NOMA
Norma opisu materiałów archiwalnych
w archiwach państwowych
dostępna na stronie NDAP
A Glossary
of
Archival and Records
Terminology

Terminologie der Archivwissenschaft
Online-Lexikon
![]()
Portail International
Archivistique Francophone
On-Line Glossaire
ICA
Multilingual
Archival Terminology